
Vector Databases in Movie Recommenders
Working through a practical example of using vector databases in a movie recommendation system for efficient, personalized suggestions.

Founder | Product Manager | Builder
Recommendation systems are all around us - they have become the default method for discovering and exploring new content. Whether it's listening to songs on Spotify, watching movies on Netflix, reading blogs on Medium, or shopping on Amazon, recommendation systems are everywhere. These systems are designed to help users make decisions and discover new content.
By analyzing user behavior and patterns through browsing history, user interactions, ratings, social media interactions, demographics, and more, companies can understand users' likes and dislikes. Today, sophisticated systems are built using advanced algorithms to predict what a user might enjoy.
In this article, we are working through an example of collaborative filtering recommendations. For a broader understanding of recommendation systems, be sure to check out our blog Recommendation Systems 101.
Role of Vector Databases in Recommendation Systems
At the heart of recommendation systems is the task of identifying similarities between items and users. This requires processing high-dimensional data that encapsulates latent item features and user preferences. Vector databases, like emno, are crucial in optimizing this process.
Managing High-Dimensional Data: Vector databases specialize in storing and managing high-dimensional data, such as user and item embeddings. These embeddings represent detailed user preferences and item characteristics, forming the backbone of effective recommendation systems.
Rapid Retrieval of Similar Items: The advanced indexing techniques used by vector databases enable quick retrieval of similar users or items by efficiently comparing their vector representations. This capability is crucial for recommendation systems handling large-scale datasets, allowing them to identify relevant connections in real time.
Precision in Recommendations: Vector databases improve the accuracy of recommendations. By efficiently comparing vectors, they ensure that the suggested items or content closely align with the user's interests, leading to more personalized and relevant recommendations.
As we dive into the specifics of implementing collaborative filtering, we'll discover how vector databases assist in the recommendation process, ensuring users receive accurate and personalized suggestions.
Collaborative filtering
Collaborative filtering models primarily rely on user-item interaction data (such as movie ratings). They identify patterns in these interactions and use them to predict how a user might rate items they haven't interacted with.
The model learns latent (hidden) features that describe both users and items (in our example, movies). These features aren't directly interpretable like explicit metadata (e.g., genre, director). They represent abstract characteristics inferred from the rating patterns.
Here, we are working with a pre-trained collaborative filtering model to recommend movies to users.
The steps are based on the Colab environment setup.
Let's begin by installing and importing all the necessary libraries. I have consolidated them in one place for clarity.
!pip install transformers
!pip install requests
!pip install pandas
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
import json
import requests
import pandas as pd
import re
from tqdm import tqdm
Next, let's load our model and dataset into our environment. Here, we are using a collaborative filtering model: https://huggingface.co/emno/movie-recommender-collaborative-filtering.
This model was trained following the steps mentioned in Collaborative Filtering Movielens using the Movielens dataset.
The key difference is that we used a subset of the dataset and a smaller embedding dimension to keep the model and embeddings lightweight for this example.
The emno model dataset contains the below files:
movie_embeddings.csv: Contains the movies along with their embeddings and metadata.movie2movie_encoded.json: Contains the mappings of the original movie IDs to sequential IDs that were used for the model training.user2user_encoded.json: Contains the mappings of the original user IDs to sequential IDs that were used for the model training.ratings.csv,movies. csvandlinks.csv: These are the files from the original dataset from Movielens.
from huggingface_hub import HfFolder
from huggingface_hub import from_pretrained_keras
model = from_pretrained_keras("emno/movie-recommender-collaborative-filtering")
# Load the dataset from the git repository and save it in Google Drive so we can load the files here
# Remember to change the pathsof the files
embeddings_file_path = '/content/drive/My Drive/emno-movie-recommender-cf-dataset/movie_embeddings.csv'
path_to_movie2movie_encoded = '/content/drive/My Drive/emno-movie-recommender-cf-dataset/movie2movie_encoded.json'
path_to_user2user_encoded = '/content/drive/My Drive/emno-movie-recommender-cf-dataset/user2user_encoded.json'
# Paths to the 'ratings.csv' and 'movies.csv' from the Movielens dataset files
ratings_file_path = '/content/drive/My Drive/emno-movie-recommender-cf-dataset/ml-latest-small/ratings.csv'
movies_file_path = '/content/drive/My Drive/emno-movie-recommender-cf-dataset/ml-latest-small/movies.csv'
# Load the mappings
with open(path_to_movie2movie_encoded, 'r') as file:
movie2movie_encoded = json.load(file)
with open(path_to_user2user_encoded, 'r') as f:
user2user_encoded = json.load(f)
Creating a collection
Before getting started, if you haven't already, sign up for a free emno account.
Also, generate an API Key from the dashboard and copy it. We need it to work with the emno APIs.
base_url = "https://apis.emno.io/collections"
token = "t_************" # Replace with your API Key
def check_or_create_collection(collection_name, token, dim, model):
headers = {"Token": token}
# Check for existing collection
response = requests.get(f"{base_url}/{collection_name}", headers=headers)
if response.status_code == 200:
# Collection exists
return response.json()
# If collection does not exist, create a new one
create_payload = {
"name": collection_name,
"config": {"dim": dim, "model": model}
}
create_response = requests.post(base_url, json=create_payload, headers=headers)
if create_response.status_code == 201:
return create_response.json()
else:
raise Exception(f"Error creating collection: {create_response.content}")
collection_name = "recommender-model" # Replace with your collection name
dim = 32 # Dimension of the embeddings
model = "CUSTOM"
collection = check_or_create_collection(collection_name, token, dim, model)
print(f"Collection ID: {collection['id']}")
Inserting the embeddings
In our collaborative filtering model, 'embeddings' are key. They are dense, low-dimensional vectors that represent users and movies. During training, these embeddings are optimized to predict user interactions, like movie ratings accurately. Specifically, a user's embedding encapsulates their preferences, while a movie's embedding is shaped by the collective ratings it receives from different users. This process allows the model to capture subtle patterns in user behavior and movie characteristics.
Now, let's insert the movie embeddings into our vector database. We'll use the movie_embeddings.csv file to load these embeddings.
batch_size = 100 # Adjust as needed
collection_id = collection['id']
headers = {"Content-Type": "application/json", "Token": token}
upload_url = f"{base_url}/{collection_id}/vectors/create"
# Function to process data into batches
def process_data(file_path, chunk_size):
# Read data
data_df = pd.read_csv(file_path)
# Process data into chunks
chunks = [data_df[i:i + chunk_size] for i in range(0, len(data_df), chunk_size)]
return chunks
# Process data into batches
data_batches = process_data(embeddings_file_path, batch_size)
# Upload data to the collection
for batch in tqdm(data_batches, desc="Uploading batches"):
# Prepare payload for batch upload
payload = [{
"content": str(item['movieId']),
"values": json.loads(item['values']),
"metadata": item['metadata']
} for item in batch.to_dict(orient='records')]
# Construct the upload URL
upload_url = f"{base_url}/{collection_id}/vectors/create"
# Upload batch
upload_response = requests.post(upload_url, json=payload, headers=headers)
if upload_response.status_code != 200:
print(f"Error uploading batch: {upload_response.content}")
print("\nUpload complete.")
Defining a method for semantic search
Here, we are defining a method for performing semantic searches on emno.
def query_emno(embedding):
url = "https://apis.emno.io/collections/c_jeFo2rITem42TPCL/query"
payload = {
"vectors": [embedding.tolist()],
"limit": 10, # Adjust the limit as needed
}
headers = {
"Content-Type": "application/json",
"Token": "t_wzotcWJALMOtGCbr"
}
response = requests.post(url, json=payload, headers=headers)
# Check the status code of the response
if response.status_code != 200:
print("Error: Received status code", response.status_code)
print("Response content:", response.content)
return None
try:
return response.json()
except json.JSONDecodeError as e:
print("JSON decoding failed:", e)
print("Response content:", response.content)
return None
Item-based Collaborative Filtering
So far, we have extracted and inserted the movie embeddings from our pre-trained collaborative filtering model into our collection. These embeddings represent movies in a learned feature space.
Next, using a sample movie from our dataset, let's see the recommendations we get for similar movies using our system.
Let's begin by printing out the details of our sample movie so we can understand the results better.
# Utility Function to safely extract data using regular expressions
def safe_extract(regex, string):
match = re.search(regex, string)
return match.group(1) if match else None
# Updated regex pattern to match titles with single quotes
title_regex = r"'title': '(.*?)'" # Non-greedy match to get the title
def convert_to_json_string(metadata_str):
return metadata_str.replace("\'", "\"").replace('\"{', '{').replace('}\"', '}').replace('"{', '\'').replace('}"', '\'')
# Load the movies data
movies_df = pd.read_csv(movies_file_path)
actual_movie_id = 112852 # Sample movie ID. You can experiment with other IDs.
movie_id_encoded = movie2movie_encoded.get(str(actual_movie_id))
# Retrieve details for the movie
queried_movie_details = movies_df[movies_df['movieId'] == actual_movie_id]
# Display the details of the movie
if not queried_movie_details.empty:
print("Finding movies similar to:",actual_movie_id )
print(queried_movie_details.to_string(index=False))
print("\n")
else:
print("Movie ID {} not found in the dataset.".format(actual_movie_id))

Next, let's get the embeddings of this movie from our model:
#Define a method to get embeddings for a specific movie from the model
def get_movie_embedding(model, sequential_id):
sequential_id_array = np.array([sequential_id])
movie_embedding_layer = model.get_layer('embedding_2')
movie_embedding = movie_embedding_layer(sequential_id_array)
return movie_embedding.numpy()[0]
# Get the movie embedding
movie_embedding = get_movie_embedding(model, movie_id_encoded)
Now, using item embedding, we perform a semantic search in emno, looking for movie embeddings that are most similar to this movie embedding using cosine similarity.
# Query emno
movie_matching_embedding_results = query_emno(movie_embedding)
# Parse the results
parsed_movie_results = []
for sublist in movie_matching_embedding_results:
for result in sublist:
metadata_str = result['metadata']
metadata_str_json = convert_to_json_string(metadata_str)
try:
metadata = json.loads(metadata_str_json)
movie_id = metadata.get('movie_id')
title = metadata.get('title')
genres = metadata.get('genres')
score = result['score']
if movie_id and title and genres:
parsed_movie_results.append({
'movie_id': movie_id,
'movies': title,
'genres': genres,
'scores': score
})
except json.JSONDecodeError as e:
# print(f"JSON parsing error: {e}")
print("")
recommendations_for_movie_df = pd.DataFrame(parsed_movie_results)
# Display the top recommendations
print("Top Recommendations for similar movies:")
print(recommendations_for_movie_df.head(10).to_string(index=False))

Interpretation of Results:
When we use a movie's embedding to find similar movies, the semantic search finds movies that are "close" to this movie in the latent feature space. This closeness is based on how users have interacted with these movies, not necessarily on explicit content(like genres, plots, directors, etc.).
So, two movies could be deemed similar based on user preferences, even if they differ significantly in content.
For example, suppose this method considers Movie A and Movie B similar. In that case, it suggests that users who liked Movie A are likely to rate Movie B similarly based on how other users have rated these movies. This similarity is drawn from the collective user rating behavior rather than specific movie attributes.
Example Scenario:
Imagine a scenario where a user likes 'Inception,' a complex, narrative-driven science fiction movie. Our system, using item-based collaborative filtering, may recommend 'The Matrix,' another film that, while different in story and style, often appeals to the same audience that enjoys intricately plotted, cerebral sci-fi films. This recommendation is derived from the observation that both movies share a similar audience profile in terms of ratings and preferences despite their distinct content features.
Conclusion:
Item-based collaborative filtering in recommendation systems is a powerful tool for finding movies that share similar user interaction patterns. This approach goes beyond traditional content-based methods, offering recommendations based on collective user behavior and preferences. As a result, users are introduced to movies that might be different in content but align closely with their viewing history and preferences.
Personalized Movie Recommendations using User Embeddings
Next, we use another technique centered around user preferences to recommend movies to a user.
For this, we obtain the user embedding from our model. This user embedding represents the user's preferences and tendencies in the same latent feature space as the movies. Here is how we do it:
def get_user_embedding(model, user_id_encoded):
user_id_array = np.array([user_id_encoded])
user_embedding_layer = model.get_layer('embedding')
user_embedding = user_embedding_layer(user_id_array)
return user_embedding.numpy()[0]
actual_user_id = 537 # Sample user ID. You can experiment with other IDs.
user_id_encoded = user2user_encoded.get(str(actual_user_id))
# Get the user embedding
user_embedding = get_user_embedding(model, user_id_encoded)
Before we get the recommendation results from our system, let's print the top 10 movies our sample user has rated highly in past interactions so we can better understand the results.
# Load the ratings data
ratings_df = pd.read_csv(ratings_file_path)
# Filter for the specified user's ratings and sort them
user_ratings_df = ratings_df[ratings_df['userId'] == actual_user_id]
user_ratings_df = user_ratings_df.sort_values(by='rating', ascending=False)
# Merge with the movies data to get the titles and genres
user_ratings_with_details_df = user_ratings_df.merge(movies_df, on='movieId', how='left')
top_10_movies = user_ratings_with_details_df.head(10)[['movieId', 'title', 'genres', 'rating']]
# Display the top 10 rated movies for the user
print("Top 10 Rated Movies by User ID:",actual_user_id)
print(top_10_movies.to_string(index=False))
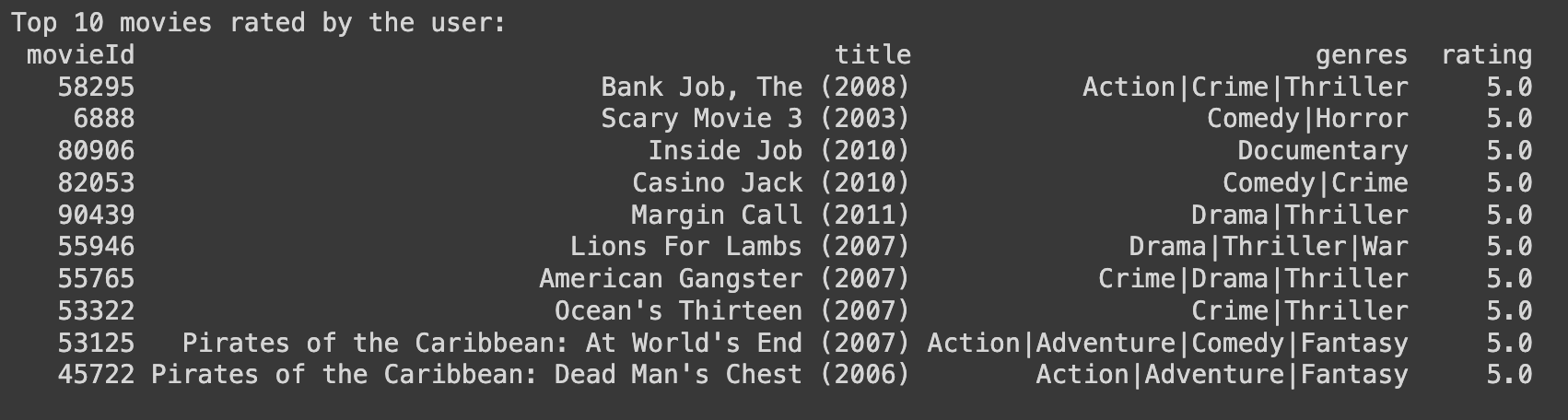
Next, using this user's embedding, we perform a semantic search in our vector database, looking for movie embeddings that are most similar to this user's embedding using cosine similarity.
We also filter out the movies the user has already watched from the search results.
# Query emno
user_matching_embedding_results = query_emno(user_embedding)
movies_watched_by_user = ratings_df[ratings_df['userId'] == actual_user_id]['movieId'].unique().tolist()
# Parse the results and track filtered movies
parsed_user_results = []
filtered_movies = [] # To keep track of filtered movies
for sublist in user_matching_embedding_results:
for result in sublist:
metadata_str = result['metadata']
metadata_str_json = convert_to_json_string(metadata_str)
try:
metadata = json.loads(metadata_str_json)
movie_id = metadata.get('movie_id')
title = metadata.get('title')
genres = metadata.get('genres')
score = result['score']
if movie_id and title and genres:
if int(movie_id) in movies_watched_by_user:
filtered_movies.append({
'movie_id': movie_id,
'movies': title,
'genres': genres,
'scores': score
})
else:
parsed_user_results.append({
'movie_id': movie_id,
'movies': title,
'genres': genres,
'scores': score
})
except json.JSONDecodeError as e:
#print(f"JSON parsing error: {e}")
print("")
recommendations_for_user_df = pd.DataFrame(parsed_user_results)
filtered_movies_df = pd.DataFrame(filtered_movies)
# Display the top 10 recommendations, excluding the movies that the user has already watched
print("Top Recommendations for User with ID:", actual_user_id)
print(recommendations_for_user_df.head(10).to_string(index=False))
# Display the filtered movies
print("\nMovies filtered out (already watched by the user):")
print(filtered_movies_df.to_string(index=False))
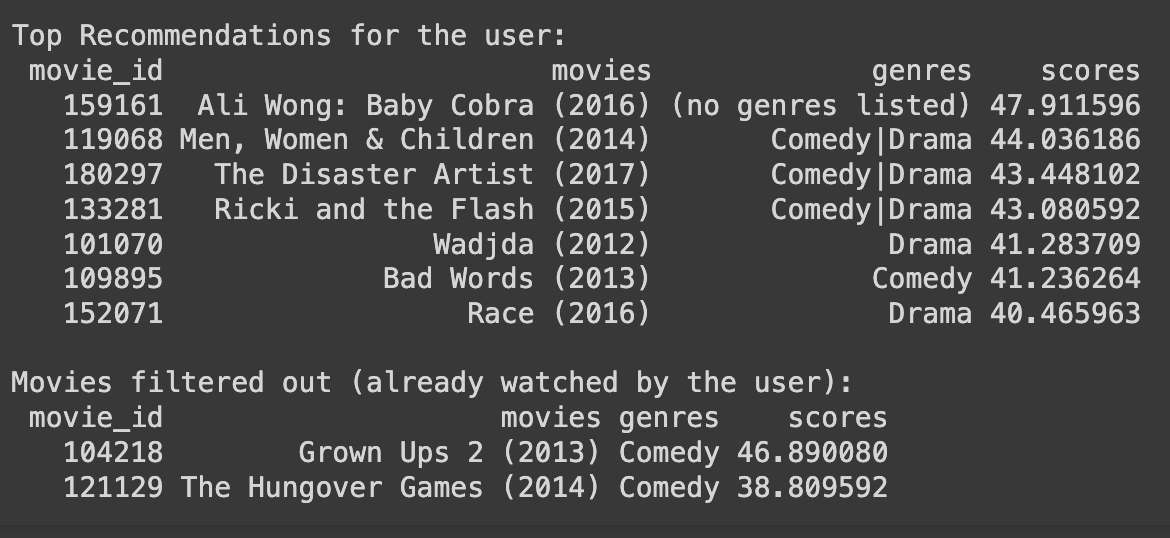
Interpretation of Results:
The result of this search is a list of movies whose embeddings are closest to the user's embedding. These movies are considered to be aligned with the user's preferences based on their interaction history (such as ratings given to other movies in the past).
The logic here is that if a user's embedding is similar to a movie's embedding, it suggests that the user is likely to have a preference or inclination towards that movie. This is because both embeddings are situated in the same feature space where proximity indicates similarity in preferences or characteristics.
Example Scenario:
For example, if a user has highly rated several sci-fi and action movies, their user embedding will be closer to other movies in the sci-fi and action genres or movies liked by similar users. Thus, the semantic search will likely return recommendations for sci-fi and action movies.
Conclusion:
By conducting a semantic search using a user's embedding against a database of movie embeddings, we are effectively finding movies that align well with that specific user's preferences. This method can provide highly personalized movie recommendations based on the learned patterns of user behavior and movie attributes from our collaborative filtering model.
Final thoughts
Our example has guided us through the inner workings of collaborative filtering, emphasizing the role of embeddings in representing user preferences and movie characteristics. We've observed how these embeddings are used to predict user-movie interactions, forming the foundation for personalized recommendations.
The seamless integration of vector databases in managing and querying these high-dimensional embeddings highlights their importance. By enabling fast and accurate retrieval of similar items, vector databases prove essential in scaling recommendation systems to handle large and complex datasets. This blog has illustrated the practical application of these concepts, showcasing how vector databases contribute to the development of efficient and scalable recommendation systems.
To access the complete code, check out our Jupyter notebook, where we walk through each step. We're excited to see what you create and would love for you to share your insights with us!



