
Recommendation Systems 101: Content & Collaborative Filtering Methods
Introduction to popular recommendation methods and their real-world applications

Founder | Product Manager | Builder
Recommendation systems are like our savvy friends who know our tastes and preferences. They're the backbone of platforms like Netflix and Amazon, guiding us to our next favorite movie or product. Today, these systems are a necessity in our digital-first world. But what makes them tick? It's a blend of user data analysis and predictive algorithms.
Business Benefits: The Driving Force Behind Recommendation Systems
Creating a robust recommendation system is a challenging yet rewarding endeavor. It requires substantial technical know-how, resources, and time investment. Companies like Spotify have spent more than a decade working on building and improving their recommendation algorithms.
Why do businesses invest in these systems? It all comes down to sales.
The goal of recommendation systems is simple: enhance user experience and engagement. Whether it's suggesting a new book on an e-commerce site or a song on a streaming service, these engines make online platforms more intuitive and user-friendly. For businesses, this translates to increased customer satisfaction and, consequently, higher revenue.
Popular models for building recommendation systems
Recommendation systems employ various methods, each with unique advantages and applications:
Content-Based Filtering
In a nutshell: "Recommend items with similar attributes."
Netflix's sophisticated recommendation system provides an excellent example of the use of content-based filtering in a hybrid system(covered later). When you watch a movie or a show, Netflix analyzes its metadata, such as genre, cast, and director. Based on these attributes, it recommends content similar to yours. For instance, if you enjoy 'Stranger Things', you might find recommendations for other science fiction shows, such as 'Black Mirror'.
Content-Based filtering method focuses on the attributes of items. It doesn't care what others are reading or liking. It's all about what you like and the specific features of the items you've interacted with.
The critical question for this method is how to determine if the two items are similar. Usually, this is done by creating an Item Content Matrix(ICM) and computing cosine similarity on such a matrix. The guiding principle is that if two items have similar attributes, we can assume that the two items are similar.
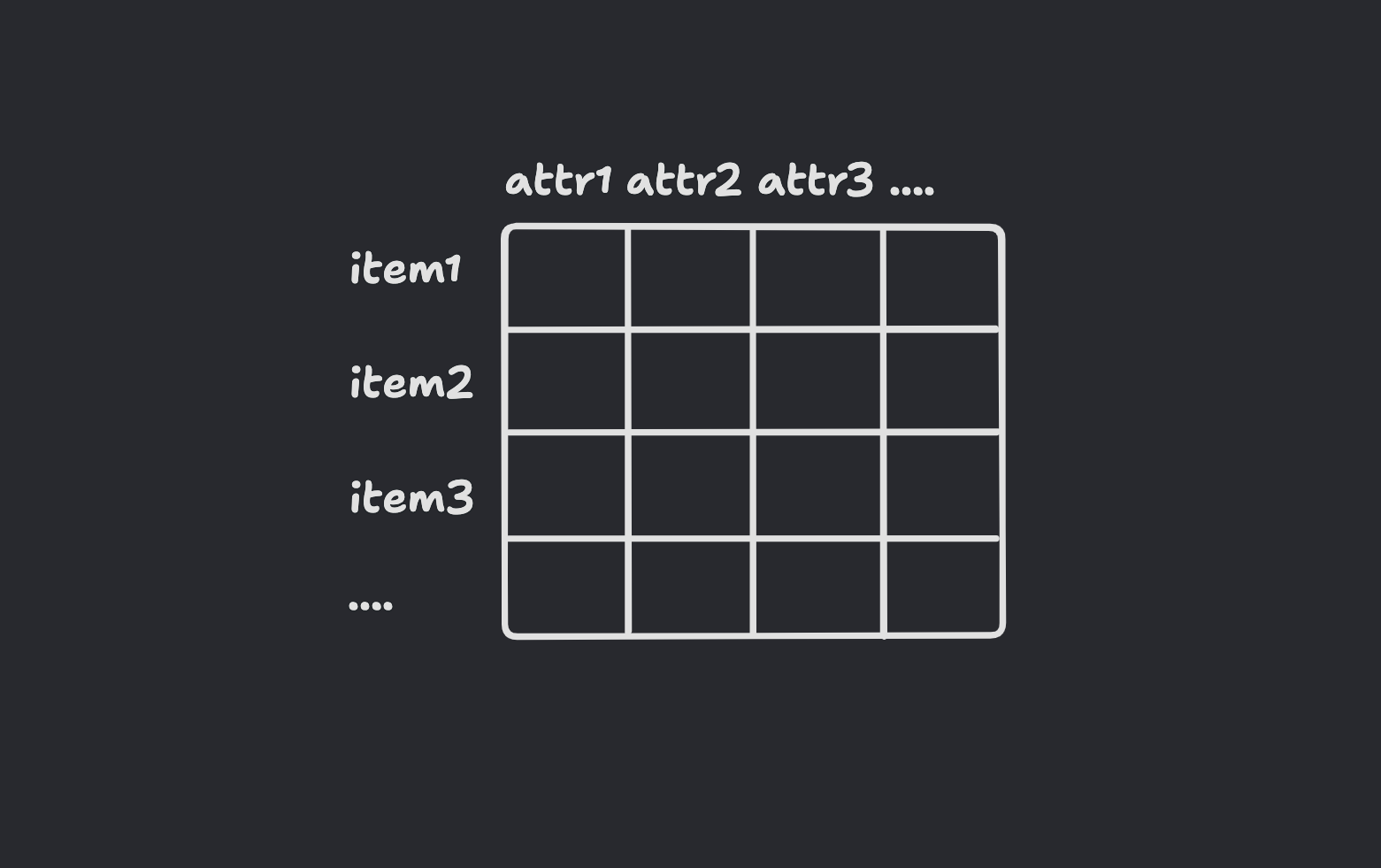
Using a simplified example of an article recommendation system, let's assume we have two datasets available to us as inputs:
Articles dataset - captures the metadata for all articles.
User Interactions dataset - captures logs of user's interactions with the articles, such as user views, likes, bookmarks, and so on.
Summarizing the steps to build such a content-based system:
Build Item Content Matrix: Use the Articles dataset to build the ICM. For example, for each article, extract features such as title, tags, description, and keywords from the content. This creates a profile for every article.

User Profile Creation: Build user profiles from their past interactions in the User Interaction dataset. We use the user profile data to query for articles with high interaction scores for each user.
One simplified way to represent it could be a JSON format, where each user, identified by a unique ID, is associated with a list of article IDs. These articles, reflective of their interactions, are accompanied by scores indicating the intensity or type of interaction.
"User_582665477366900487": { "Article_515531013045220470": 1 }, "User_6316613156648676087": { "Article_8605423472891112686": 1 }, "User_3829784524040647339": { "Article_5253644367331262405": 0.35294117647058826, "Article_3495098006178009360": 0.23529411764705882, "Article_5111115201913219115": 0.35294117647058826, "Article_5658245291907121574": 0.058823529411764705 },Recommendation Process:
Get the user's highest-scored articles from the User Profile.
Retrieve articles similar to high-scoring articles from the Item Content Matrix using techniques like cosine similarity. Utilizing a vector database, such as emno, for storing and quickly querying vectors can significantly improve the speed and accuracy of identifying similar items, thereby optimizing the recommendation process.
Filter out any articles the user has already interacted with.
Recommend top K articles with the highest similarity scores to the user.
Such a model is effective when the system needs to focus on individual user preferences, and the item metadata is rich and detailed. However, it can suffer from overspecialization. The method tends to limit recommendations to items similar to those already liked and may struggle to capture evolving interests or recommend diverse content outside the user's established profile.
Collaborative Filtering
Collaborative filtering focuses on the relationships between users and the items they interact with. It operates on the similarity principle, following a "users who liked this also liked that" logic. The goal is to predict how a user might rate items they haven't yet encountered by analyzing the preferences of similar users and the items they've interacted with. Unlike other methods, collaborative filtering does not rely on item metadata; instead, it's grounded in the user community's collective ratings and opinions.
This method typically uses a Utility Matrix (UM) as the foundation for making recommendations. A Utility Matrix represents the utility (or value) of items for users. The utility can be based on various quantifiable interactions. These interactions can be explicit, such as directly rating an article, or implicit, like simply viewing an article. Recommendation systems employing collaborative filtering may leverage either type of interaction or a combination of both to inform their suggestions.
Among the various collaborative filtering strategies, two prominent ones are User-Based filtering and Item-Based filtering. Each approach offers a unique angle on leveraging user interaction data to provide relevant and personalized recommendations.
User-Based Collaborative Filtering
In a nutshell: "Recommend items liked by users with similar preferences to user X."
Instagram's recommendation system serves as a classic case of user-based collaborative filtering, albeit as part of a hybrid approach. The platform suggests content like posts or stories based on the preferences of users with similar interests and interactions. If you frequently engage with travel-related content, Instagram is likely to show you similar content from other travel enthusiasts, leveraging the shared interests among its user base.
User-based essentially mimics recommendations from a circle of like-minded friends. It operates under the premise that if two users have exhibited similar tastes, such as enjoying the same books or movies, they will likely appreciate similar items in the future, too. This method focuses less on the specific characteristics of items and more on identifying patterns of likes and dislikes among users.
In this method, an important step is how to determine if the two users are similar. Usually, this is done by analyzing the UM and computing cosine similarity on such a matrix. The users who have rated various items similarly are assumed to have comparable tastes. The higher the overlap in ratings, the more similar the users are considered. Once similar users are identified, their preferences are used to recommend the highest-rated items that the target user hasn't encountered yet.
Summarizing the steps to build such a system using our simplified example of article recommendation:
Creating a Utility Matrix (UM): Build a Utility Matrix (UM) with rows representing users and columns representing items (such as articles). Each cell in this matrix contains the interaction score of a user for the corresponding item.
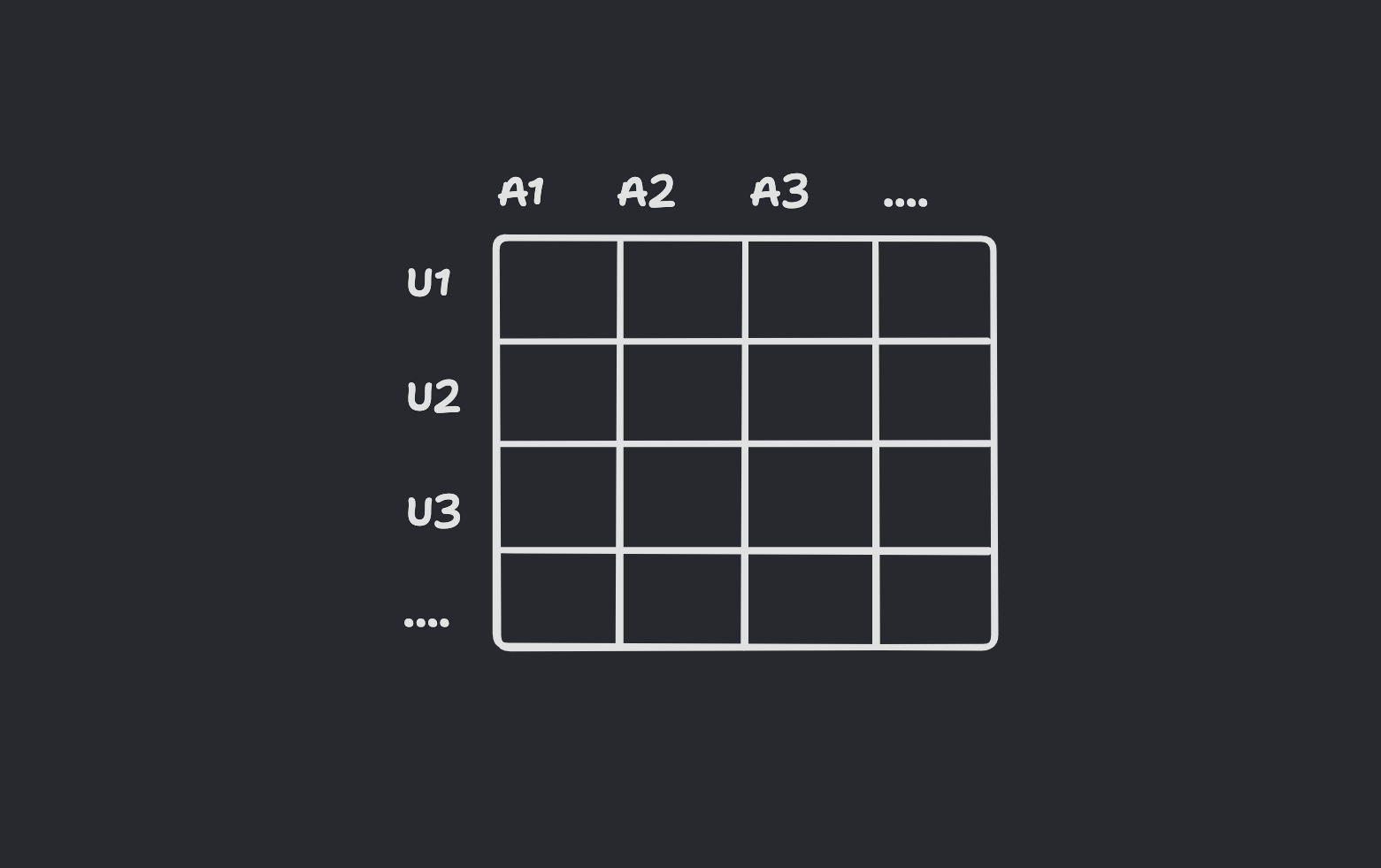
Recommendation Generation:
For the target user, we identify similar users from the Utility Matrix by using techniques like cosine similarity.
Now, we find the overall highest-rated articles based on the tastes of the top similar users. One way to do this could be to calculate the average rating for every article by similar users. Sort these items based on their average scores, from highest to lowest.
Filter out the items the target user has already interacted with. The remaining articles are potential items to recommend.
Recommend the top K items from this filtered and sorted list.
In practice, this approach can be computationally intensive, especially for large user bases. Moreover, new users pose a challenge (known as the cold start problem) because they have little to no rating history for similarity analysis.
Despite these challenges, user-based collaborative filtering remains a popular recommendation strategy, especially in platforms where user preference data is abundant and reliable.
Item-based Collaborative Filtering
In a nutshell: "Other people who liked this item also liked this other item, so you might like it too."
Imagine you're shopping on Amazon, and you buy a blender of a specific brand. Amazon may recommend other related kitchen items, like a food processor or a hand mixer, frequently bought together with that blender by other customers. This approach is based on the principle that customers who bought one item (the blender) are likely to be interested in similar or complementary items (like food processors) based on the buying patterns of similar users. This item-based filtering is part of the complex hybrid system that Amazon employs for a more comprehensive user experience, which we will explore later.
The item-based collaborative filtering method, similar to the user-based collaborative filtering, relies on the "wisdom of the crowd" principle—leveraging the preferences of a group who share similar tastes, regardless of the specific content of the items.
In this method of recommendation, predicting a user's interest in a particular item involves identifying items that closely resemble the target item. The key lies in calculating the similarity between pairs of items based on the number of users who have rated both. This similarity score is then used with the user's existing ratings to predict their potential interest in new or target items.
Taking our simplified example of an article recommendation system forward:
Creating a Utility Matrix: Build a Utility Matrix (UM) with rows representing articles and columns representing users. Notice that this is a transpose of the matrix we used in User-based collaborative filtering. Each cell in this matrix contains the interaction score of a user for the corresponding item.
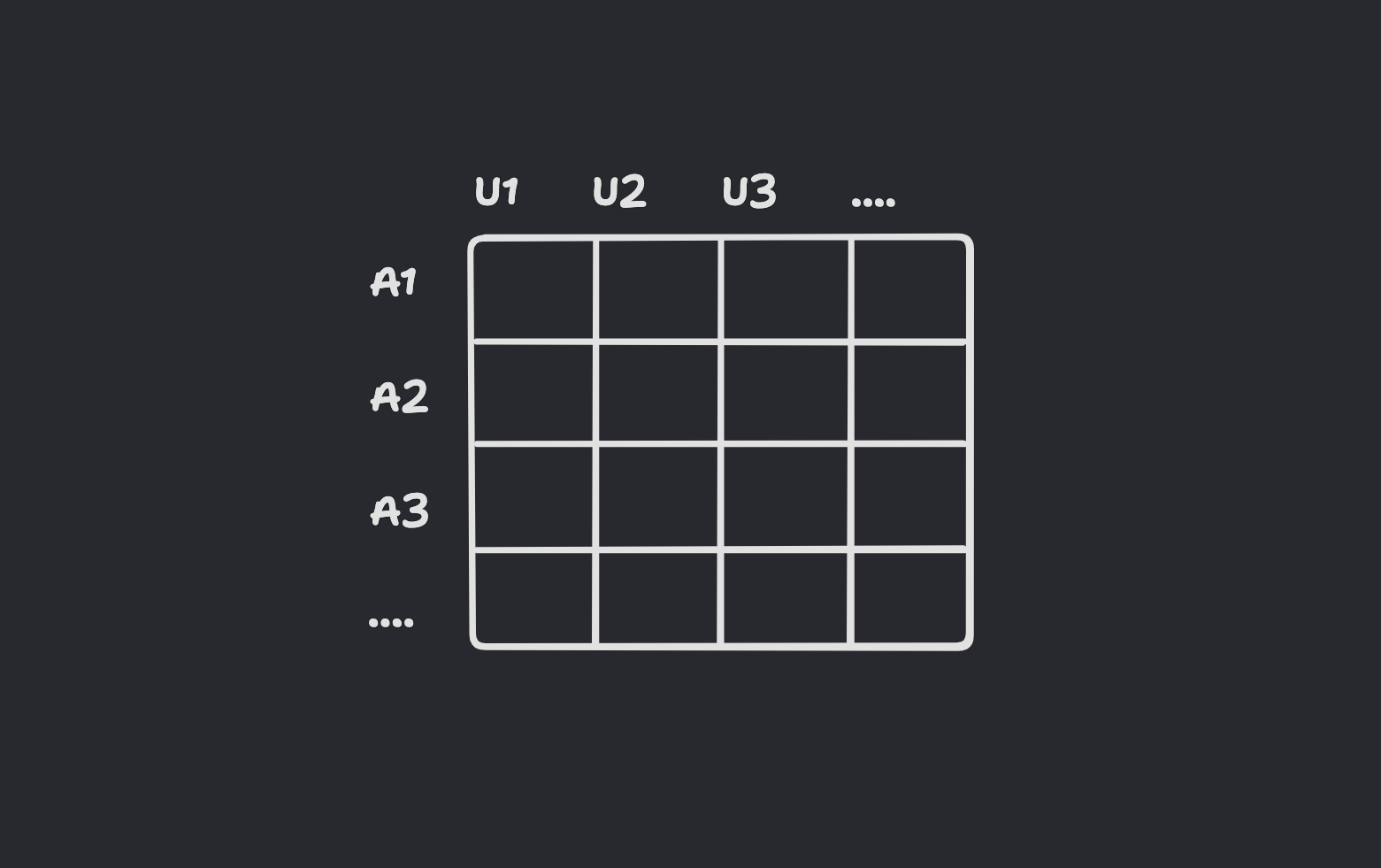
Recommendation Generation:
We identify the articles with the highest interaction scores from the User Profile for the target user.
Now, for these retrieved articles, we find similar articles from the Utility Matrix using techniques such as cosine similarity. Here, the similarity calculation is based on the pattern of user interactions. For instance, if two articles are often rated similarly by users, they are considered similar. Sort the results based on their average scores from highest to lowest.
Filter out the articles the target user has already interacted with. The remaining articles are potential items to recommend.
Recommend the top K articles from this filtered and sorted list.
One challenge with this approach is the "long tail" problem, where less popular items get fewer recommendations. The "cold-start" problem for new items is also significant, as these items lack sufficient user interactions for accurate similarity calculations.
Memory-based vs. Model-based Collaborative Filtering
Collaborative filtering models are diverse. They can also be broadly classified into two additional types: memory-based and model-based collaborative filtering.
Memory-based Collaborative Filtering: The models we have discussed so far are memory-based models that leverage Utility Matrix (UM) to find similarities between users or items. These are relatively straightforward to implement and do not require detailed item or user metadata. Memory-based methods are effective when the user base is static or moderately growing. However, they can become cumbersome with frequent new user additions. Introducing a new user requires adding them to the UM and recalculating their similarity with all existing users. This process can be computationally intensive.
A good illustration of memory-based filtering in action is Spotify's playlist recommendations. Spotify leverages your listening history to create personalized playlists. For instance, if you're a fan of jazz music, it recommends other jazz tracks popular among similar listeners. This method is straightforward, focusing on user interactions and preferences, but it can face scalability issues when dealing with large datasets.
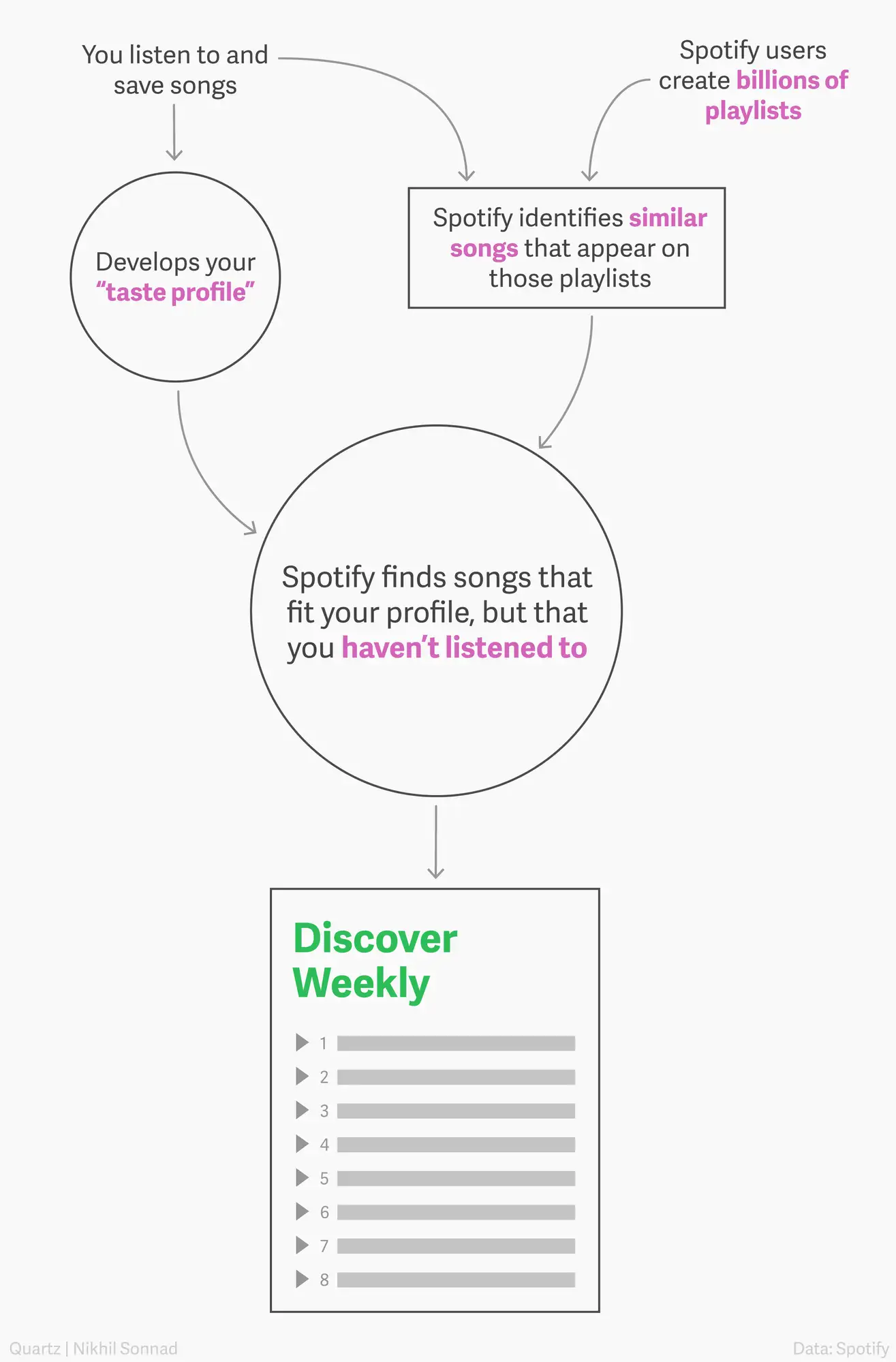
Model-based Collaborative Filtering: In contrast to memory-based filtering, model-based methods use machine learning to forecast user preferences. The process involves building a sophisticated model from training data and then estimating ratings based on the model and user profiles. These models are adept at handling large, complex datasets and offer scalability advantages. They're particularly effective in dynamic environments with a constantly growing user base.
Netflix utilizes model-based filtering for its diverse recommendations. Employing machine learning techniques like matrix factorization, Netflix's algorithms delve into user-item interactions to suggest content. This method can recommend a broader range of content, such as suggesting a drama series to a thriller enthusiast, by identifying underlying patterns in viewer preferences. It stands out for its ability to handle varied and extensive datasets, offering personalized recommendations beyond straightforward genre matches.
Selecting the Ideal Recommendation Technique with Hybrid Approaches
In recommendation systems, there's no one-size-fits-all solution. It's all about deploying tailored models suited to specific scenarios and objectives. While content-based and collaborative filtering methods each have their strengths, the current digital landscape often calls for a more nuanced approach. This is where hybrid recommendation systems come into play, blending the best elements of both content-based and collaborative filtering techniques.
Hybrid Methods: The Best of Both Worlds
Many leading platforms, such as Netflix, Amazon, Spotify, Instagram, and others, have pioneered the use of hybrid recommendation systems. These systems combine the insights gained from user behavior (collaborative filtering) with the attributes of the items themselves (content-based filtering). Netflix, for instance, creates a holistic view of your preferences by analyzing both the genres and specific titles you watch, along with the viewing patterns of users with similar tastes. Amazon's approach is similar, recommending products based not only on your purchase history but also on the characteristics of the products themselves and purchasing patterns of similar users.
Such hybrid systems effectively overcome the limitations inherent in purely content-based or collaborative approaches. Purely content-based systems, while adept at matching specific item attributes to user preferences, often limit the discovery of diverse content. Collaborative filtering, on the other hand, relies heavily on user interactions and can miss out on recommending newer or less popular items due to the absence of sufficient user data. Hybrid systems address these challenges by integrating the strengths of both methods. They not only cater to a user’s specific preferences but also introduce them to new and varied content based on broader user behavior trends. This results in a richer, more dynamic recommendation experience that is both relevant and exploratory.
Navigating the Complexity of Hybrid Systems
Implementing a hybrid recommendation system is not without its challenges. It demands a strategic blend of various techniques, ensuring that each component complements the others effectively. This delicate balancing act aims to provide a comprehensive yet focused set of recommendations, avoiding overwhelming users with too many choices or limiting the scope too narrowly.
Moreover, the development and maintenance of these systems require a dedicated effort. Continual refinement and adaptation of these algorithms are crucial for keeping pace with changing user behaviors and preferences. This often necessitates a team of skilled machine learning experts tasked with the ongoing evolution and optimization of the recommendation engine.
In conclusion, hybrid recommendation systems represent a sophisticated convergence of different methodologies. By leveraging the strengths of both content-based and collaborative filtering, they offer a refined, dynamic, and user-centric approach to recommendations.
Conclusion
Recommendation systems, integral to our digital experiences, continue to evolve, offering increasingly personalized and intuitive suggestions. As we move forward, these systems will become even more sophisticated, harnessing advancements in AI and machine learning to understand and cater to user preferences in new ways. As such, improvements in these systems will continue to improve our digital interactions, making our online experiences more tailored, engaging, and intuitive.



